红楼梦十二金钗游戏资源分析(九)
之前写了一个系列分析红楼梦十二金钗的文件格式,现在又接触了一些工具, 再加上又翻出了之前的 cpu log,感觉这是命运的指引, 看看这次我们能不能翻出点新花样来。
目录
本系列已完结,以下是各章节说明,17 之前是 dos 版相关,之后是 2001 版:
- 背景、简单分析
- 显存位置
- 事件图保存算法: LZW
- 调色板
- MGP2
- 结局图
- 事件图中的眼睛
- 音频文件
- 按位读取
- 循环之前
- 读取循环
- 重现 LZW
- PAT 的图形格式
- STAFF 调色板
- 字体文件
- 脚本解密
- 版本比较
- 第一张图
- 调色板1
- 第二张图
- 调色板2
- 调色板处理
- 静态事件图、结局图
- 动态图、鉴赏模式
使用到的工具
- ghidra:我是经过 cutter 知道还有这样一款工具,由于 cutter 对于我们这个游戏执行文件支援得不是很好,所以我们这次用了 ghidra
- klogg:是的,我们还是要用这个来看 cpu log
开始
我们第一步自然是在 ghidra 中找到读取索引的循环位置,根据以前我们的分析,
程序在 0207:00003C57 处读出数据,仔细看一下上下文:
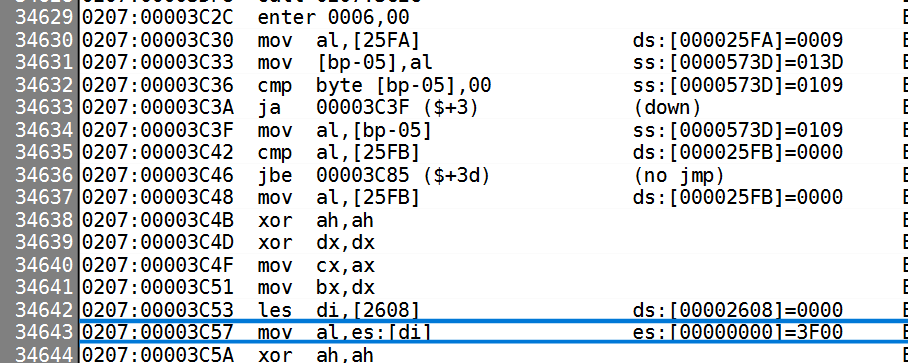
这个函数是从 3c2c 开始的,幸运的是,ghidra 原始对函数的命名,
也是根据地址位置来进行命名的,所以我们可以轻松找到这个函数:
看一下它的内容:

这就和上面 cpu log 的内容对上了。同时我们可以看到,
ghidra 的 1018 其实就相当于 dosbox 的 0207,这个我猜可以改到两边对应相同,
不过我是新手,还没研究怎么使用。
FUN_1018_3c2c → load_bits_by_len
ghidra 有一个功能是给识别到的变量重命名,所以我们可以让这个函数更容易理解一点:
uint __cdecl16far load_bits_by_len(void)
{
uint uVar1;
uint uVar2;
byte load_bit_len;
uint local_6;
load_bit_len = CURRENT_BIT_LEN;
while (load_bit_len != 0) {
if (LOAD_BUFFER_LEN < load_bit_len) {
uVar2 = 0;
uVar1 = FUN_1048_0efe();
DAT_1050_25fc = uVar1 | DAT_1050_25fc;
DAT_1050_25fe = uVar2 | DAT_1050_25fe;
LOAD_BUFFER_LEN = LOAD_BUFFER_LEN + 8;
FUN_1008_3efa(1,(int)&IMAGE_BUFFER_IDX,0x1050);
}
else {
local_6 = (1 << (load_bit_len & 0x1f)) - 1U & DAT_1050_25fc;
DAT_1050_25fc = FUN_1048_0ee5();
LOAD_BUFFER_LEN = LOAD_BUFFER_LEN - load_bit_len;
load_bit_len = 0;
}
}
return local_6;
}
我们首先可以识别的应该是 load_bit_len 以及 CURRENT_BIT_LEN,
前者是函数中的变量,后者是全局变量,我们知道这个长度是会慢慢增长的,
而且有一个上限。所以函数先取出这个值,然后与另一个值进行对比,
那么与它对比的值就是缓冲区当前的长度了,我们叫它 LOAD_BUFFER_LEN,
所以循环内两个分支的作用也就很清楚了,这样一来,这个函数其实就很容易理解了:
- 取出当前索引长度,判断缓冲区是否有足够数据
- 如果不够,则读取一个 byte,重新判断
- 如果够,则读取索引返回
接下来我们有两个方向,一个是看哪里引用了 load_bits_by_len,
另一个是看 load_bits_by_len 中的几个子函数做了什么。
我们不妨先看看能不能把这个函数完全吃透。
FUN_1048_0efe → shift_left_ax_by_cx
首先我们知道 1048 对应了 dosbox 的 0277
这个函数很简单,但是其实很难看出什么,因为它的计算依赖于一个全局地址
DAT_1050_1470,和寄存器的值,先看看这个全局地址:
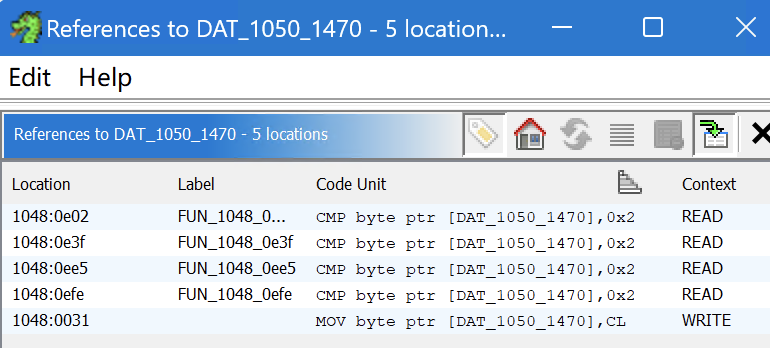
ghidra 告诉我们,这个地址在程序一开始执行的时候就已经被确定了, 我们在 cpu log 中,也没有看到过这个值有过变化:

永远是 3,这个值如何确定的呢?回到 ghidra 1048:0031:
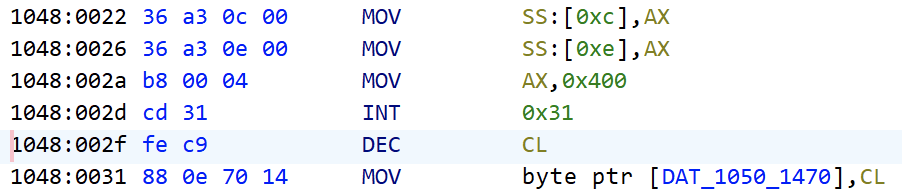
所以它是和中断有关,这个 int 31h 又是做什么的呢?
根据这里的信息,
这是去获取 DOS Protected Mode Interface 的版本,286 返回 2,386 返回 3,
我们这里一直是 3,考虑到后面的减 1,我们是 486。
那么我们索性把这个变量改名为 CPU_TYPE,而且这样与它相关的判断,
我们都只看一半就好,那其实这个函数只剩一行了,就是根据 c 的值,左移 a:
int __cdecl16far FUN_1048_0efe(void)
{
int in_AX;
uint in_CX;
uint uVar1;
if (CPU_TYPE < 2) {
for (uVar1 = in_CX & 0x1f; uVar1 != 0; uVar1 = uVar1 - 1) {
in_AX = in_AX << 1;
}
return in_AX;
}
return in_AX << ((byte)in_CX & 0x1f);
}
为什么有 & 0x1f,我觉得是为了防越界,可能没什么用。
排除了全局变量,那么函数就只和寄存器 a 和 c 的值有关了,根据调用前的程序:

cx 保存了缓冲区的数据长度,al 保存了当前文件的内容,
似乎我们不能修改 ghidra 生成的内容,但是我们可以写点注释。
接下来是 25FC 和 25FE 两个地址。这两个地址的作用需要看一下 cpu log:
0277:00000F05 shld dx,ax,cl EAX:000000DE EBX:00010000 ECX:00000009 EDX:BEEA0000 ESI:00000070 EDI:00000820 EBP:00005742 ESP:00005738 DS:0287 ES:03BF FS:0000 GS:0000 SS:028F CF:0 ZF:0 SF:0 OF:0 AF:0 PF:0 IF:1
0277:00000F08 shl ax,cl EAX:000000DE EBX:00010000 ECX:00000009 EDX:BEEA0001 ESI:00000070 EDI:00000820 EBP:00005742 ESP:00005738 DS:0287 ES:03BF FS:0000 GS:0000 SS:028F CF:0 ZF:0 SF:0 OF:0 AF:0 PF:0 IF:1
0277:00000F0A retf EAX:0000BC00 EBX:00010000 ECX:00000009 EDX:BEEA0001 ESI:00000070 EDI:00000820 EBP:00005742 ESP:00005738 DS:0287 ES:03BF FS:0000 GS:0000 SS:028F CF:1 ZF:0 SF:1 OF:1 AF:1 PF:1 IF:1
0207:00003C63 or ax,[25FC] ds:[000025FC]=00A1 EAX:0000BC00 EBX:00010000 ECX:00000009 EDX:BEEA0001 ESI:00000070 EDI:00000820 EBP:00005742 ESP:0000573C DS:0287 ES:03BF FS:0000 GS:0000 SS:028F CF:1 ZF:0 SF:1 OF:1 AF:1 PF:1 IF:1
0207:00003C67 or dx,[25FE] ds:[000025FE]=0000 EAX:0000BCA1 EBX:00010000 ECX:00000009 EDX:BEEA0001 ESI:00000070 EDI:00000820 EBP:00005742 ESP:0000573C DS:0287 ES:03BF FS:0000 GS:0000 SS:028F CF:0 ZF:0 SF:1 OF:0 AF:0 PF:0 IF:1
0207:00003C6B mov [25FC],ax ds:[000025FC]=00A1 EAX:0000BCA1 EBX:00010000 ECX:00000009 EDX:BEEA0001 ESI:00000070 EDI:00000820 EBP:00005742 ESP:0000573C DS:0287 ES:03BF FS:0000 GS:0000 SS:028F CF:0 ZF:0 SF:0 OF:0 AF:0 PF:0 IF:1
0207:00003C6E mov [25FE],dx ds:[000025FE]=0000 EAX:0000BCA1 EBX:00010000 ECX:00000009 EDX:BEEA0001 ESI:00000070 EDI:00000820 EBP:00005742 ESP:0000573C DS:0287 ES:03BF FS:0000 GS:0000 SS:028F CF:0 ZF:0 SF:0 OF:0 AF:0 PF:0 IF:1
两者应该都是二字节缓冲区的内容,一个保存位移后的 ax,一个保存 shld 的 dx。
所以目前读取到缓冲区我们只剩下一个函数 FUN_1008_3efa
FUN_1008_3efa → offset_file_buffer
函数接收了两个参数,一个 1,一个文件的索引位置
void __stdcall16far FUN_1008_3efa(uint param_1,uint *param_2)
{
int iVar1;
undefined2 uVar2;
uVar2 = (undefined2)((ulong)param_2 >> 0x10);
iVar1 = *(int *)((int)param_2 + 2);
if (CARRY2(*param_2,param_1)) {
iVar1 = iVar1 + CONSTANT_24;
}
*param_2 = *param_2 + param_1;
*(int *)((int)param_2 + 2) = iVar1;
return;
}
如果缓冲区的地址加 1 进位(越界)了,文件索引段地址要移动到下一个位置,
注意这个 CONSTANT_24,ghidra 显示这是一个常量,值为 24,
但是其实 cpu log 中,这个值为 8,所以可能有其他地方修改了值,
但是 ghidra 无法侦测到,不过因为他只是检查读取越界,这整个函数我们都可以忽略,
意义不大。
文件到缓冲区的部分,我们已经完全清楚了,那么 load_bits_by_len
我们只剩下从缓冲区读取出索引值的部分:
local_6 = (1 << (load_bit_len & 0x1f)) - 1U & DAT_1050_25fc;
DAT_1050_25fc = FUN_1048_0ee5();
LOAD_BUFFER_LEN = LOAD_BUFFER_LEN - load_bit_len;
load_bit_len = 0;
local_6 其实就是读取到的索引值,这样写可能比较难懂,我们简化一下:
int mask = (1 << load_bit_len) - 1;
local_6 = mask & BUFFER_2BYTES_AX
所以索引就从这个 2 字节 buffer 中提取出来,那么我们只剩下一个函数了。
FUN_1048_0ee5 → clear_buffer_by_bit_len
这个其实不看也猜得出来,索引已经读出来了,我们要把数据从缓冲区清除。
uint __cdecl16far FUN_1048_0ee5(void)
{
byte bVar1;
uint uVar2;
uint in_AX;
uint in_CX;
uint uVar3;
uint in_DX;
if (CPU_TYPE < 2) {
for (uVar3 = in_CX & 0x1f; uVar3 != 0; uVar3 = uVar3 - 1) {
uVar2 = in_DX & 1;
in_DX = in_DX >> 1;
in_AX = in_AX >> 1 | (uint)(uVar2 != 0) << 0xf;
}
return in_AX;
}
bVar1 = (byte)in_CX & 0x1f;
return in_AX >> bVar1 | in_DX << 0x10 - bVar1;
}
这个函数依赖了三个寄存器 ACD,A 的值就是读取的索引,C 就是索引长度,
D 是前面保存的 shld 的结果。
总结
现在 load_bits_by_len 应该对我们来说没有秘密可言了:
uint __cdecl16far load_bits_by_len(void)
{
uint uVar1;
uint uVar2;
byte load_bit_len;
uint current_index;
load_bit_len = CURRENT_BIT_LEN;
while (load_bit_len != 0) {
if (CURRENT_BUFFER_LEN < load_bit_len) {
uVar2 = 0;
/* load file buffer to al,
load buffer len to cl */
uVar1 = shift_left_ax_by_cx();
BUFFER_2BYTES_AX = uVar1 | BUFFER_2BYTES_AX;
BUFFER_2BYTES_DX = uVar2 | BUFFER_2BYTES_DX;
CURRENT_BUFFER_LEN = CURRENT_BUFFER_LEN + 8;
offset_file_buffer(1,(int)&FILE_BUFFER_IDX,0x1050);
}
else {
current_index = (1 << (load_bit_len & 0x1f)) - 1U & BUFFER_2BYTES_AX;
BUFFER_2BYTES_AX = clear_buffer_by_bit_len();
/* update BUFFER_2BYTES_AX
update BUFFER_2BYTES_DX */
CURRENT_BUFFER_LEN = CURRENT_BUFFER_LEN - load_bit_len;
load_bit_len = 0;
}
}
return current_index;
}
似乎也没有什么意外的地方,不过 ghidra 对 shld/shrd 的处理看上去更简单,
后面我们会去看调用 load_bits_by_len 的逻辑。