红楼梦十二金钗游戏资源分析(十二)
看懂容易,写起来还是困难
目录
本系列已完结,以下是各章节说明,17 之前是 dos 版相关,之后是 2001 版:
- 背景、简单分析
- 显存位置
- 事件图保存算法: LZW
- 调色板
- MGP2
- 结局图
- 事件图中的眼睛
- 音频文件
- 按位读取
- 循环之前
- 读取循环
- 重现 LZW
- PAT 的图形格式
- STAFF 调色板
- 字体文件
- 脚本解密
- 版本比较
- 第一张图
- 调色板1
- 第二张图
- 调色板2
- 调色板处理
- 静态事件图、结局图
- 动态图、鉴赏模式
复用的东西
我之前解析时也写过一些工具,比如按位读取,以及 LZW 的解码, 主要是根据 cpu log 中数据的变化,推断程序是如何运行的。 所以这个代码在分析某些资源时,会有一些问题,现在我们有了一个更高的维度, 所以可以更加贴切还原处理的过程,不过这也不是说之前我们分析的代码完全没用, 重新利用一些之前的东西,能帮我们更快达成目标。以下几种情况我都用了之前的代码
- mgp2 文件的拆解
- 按位读取的操作
- 调色板
而且这次我没有去考虑读取内容的生命周期,因为我们主要目标是把图像还原出来, 所以文件内容会有大量的复制。所以本文也不会涉及这两方面。 不过按位读取与之前略有不同,我们后面会提到。
前言+TLDR
代码我们放在循环的部分,我们之前分析过,这是 LZW,确实是,但是还是有一些不同,当然也可能是我见识少。 首先我们看核心的部分,字典。
字典
pub fn reset(&mut self) {
self.bit_len = 9;
self.last_dict_index = INIT_DICT_INDEX;
self.dict = vec![DictItem::new(); DICT_LEN];
for i in 0..256 {
self.dict[i].index = DICT_COLOR_INDEX;
self.dict[i].color = i as u8;
}
}
pub fn add_index(&mut self, color_index: u16, color: u8) {
let index = self.last_dict_index as usize;
let item = &mut self.dict[index];
item.index = color_index;
item.color = color;
self.last_dict_index += 1;
}
pub fn get_color_vec_by_index(&self, index: u16) -> Vec<u8> {
let mut vec = vec![];
let mut dict_index = index as usize;
loop {
let dict_item = &self.dict[dict_index];
vec.push(dict_item.color);
if dict_item.index == DICT_COLOR_INDEX {
break;
}
dict_index = dict_item.index as usize;
}
vec.reverse();
vec
}
字典是一个长度为 1000h 的数组,我们之前有提,按位读取的最大长度不会超过 12,
这就是原因了,因为 1000h = 0001_0000_0000_0000b,12 个 0。
由于这是一个数组,其下标对应要查找的颜色索引,而数组存储的内容包含一个索引, 一个颜色。所以这就是一个链式结构了,因为我们可以在一个索引里套用另一个索引, 而套用的索引也是包含了一个索引和一个颜色,这样就可以带出一串颜色出来。
那么程序如何判断这个索引是否是纯颜色呢,我们知道纯颜色应该是小于 256,
但是程序没有这么做,程序在重设字典时,把前 256 个索引中存储的索引值设定为 7fffh,
当程序读取到「索引中保存的索引值」为 7fffh 时,就知道了,这是一个颜色,循环中止。
这个字典的设计中其实有一个问题,如果索引中保存的索引和自身相同, 那么这个取色循环是无法退出的,这一点在调试的时候可能会经常遇到。 因为程序上是没有对这一情况进行任何处理的,所以只有保证数据完全正确,才不会出现死循环的情况。
循环,按位读取(更新)
闲话少叙,直接上代码:
self.read(); // 100
self.reset();
let mut last_index = self.read();
let mut pix_vec = self.get_color_vec_by_index(last_index);
loop {
let crt_index = self.read();
if crt_index == 0x100 {
self.reset();
last_index = self.read();
pix_vec.append(&mut self.get_color_vec_by_index(last_index));
continue;
}
if crt_index == 0x101 {
break;
}
let dict_color = if crt_index >= self.last_dict_index {
self.get_color_by_index(last_index)
} else {
self.get_color_by_index(crt_index)
};
self.add_index(last_index, dict_color);
pix_vec.append(&mut self.get_color_vec_by_index(crt_index));
last_index = crt_index;
}
我们知道 LZW 是读取「一定长度」的数据来转换为索引,对于这个游戏,
这个「一定长度」是从 9 到 12 变化,那么什么时候长度加一就变得很重要,
因为一旦加一的时机错了,后面的数据就全错了。
程序中,这个时机在于当前字典的最大索引,当前字典的最大索引产生进位时
(512 → 1024,1024 → 2048),这时按位读取的长度就要对应加一。
即便如此,如果我们直接按这个逻辑还原程序,还是会有问题,因为程序读取文件内容时还有一些细节:
- 程序默认第一个读到的索引(
100)没用,直接丢掉了,第二个值一定是颜色,并且直接当成「上一索引」进入循环,这个问题不大。后面每次读取到100,除了重设字典,我们都需要再读一个值作为「上一索引」。注意这两个读取,由于没有建立索引,所以不会影响读取长度的变化。 - 我们确实会读取到没有收录到字典的索引,对于这种情况,程序是使用「上一索引」,先读出最后的颜色(索引最深处),然后根据上一索引和最后的颜色去建立新的索引。
- 除去步骤 1 中的读取例外,循环中的读取都会固定创建一个索引。也就是说,可能这个算法不会产生重复意义的索引,也可能是程序只是无脑建一个新的就好。
总结
以上就是我们这次的收获,之前我们画场景时会有一些资源没有解出的情况, 现在也可以顺利解出了,比如之前我们提到的解析报错的 AREA 106:

看得出来边上是有一些不太和谐的像素,可能也就是为啥当时我们没能解出来的原因, 顺带一提,FACE 也是毫无压力:
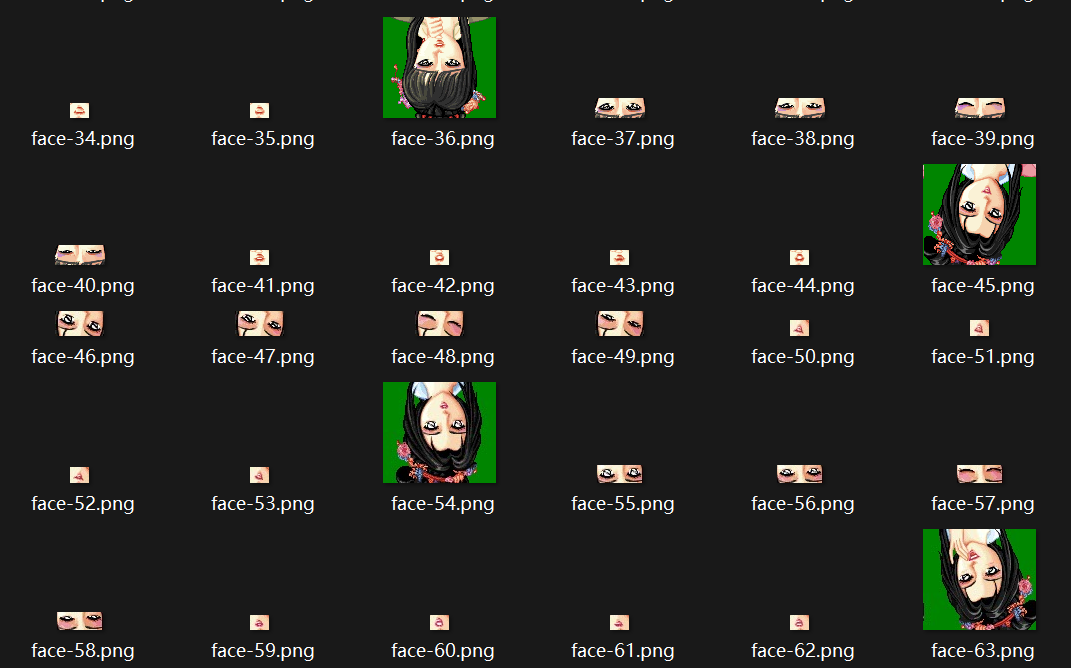
图是反的,正向显示需要再做一些处理,另外如果你对游戏还有印象的话,头像是会说话和眨眼的, 这些元素都在 FACE.PAT。
好了,红楼梦 LZW 的部分我们现在应该是破案了,代码我还想抽时间再整理一下, 就还没放出来,需要讨论的朋友应该知道怎样可以联系到我。