红楼梦十二金钗游戏资源分析(三)
今天我们来看一下 EVENT.PAT 中的第一张图是如何保存的。本文可能会比较无聊, 因为着重于讲述图像的读取机制,以及我在实践中遇到的问题。
目录
本系列已完结,以下是各章节说明,17 之前是 dos 版相关,之后是 2001 版:
- 背景、简单分析
- 显存位置
- 事件图保存算法: LZW
- 调色板
- MGP2
- 结局图
- 事件图中的眼睛
- 音频文件
- 按位读取
- 循环之前
- 读取循环
- 重现 LZW
- PAT 的图形格式
- STAFF 调色板
- 字体文件
- 脚本解密
- 版本比较
- 第一张图
- 调色板1
- 第二张图
- 调色板2
- 调色板处理
- 静态事件图、结局图
- 动态图、鉴赏模式
TLDR: LZW
图像以类似 lzw 的方式保存,不过我不能确定这是否是标准的 lzw 的做法,因为实际解析的过程中,有一些特殊处理。
文件读取
程序每次从文件读取一个字节,放入一个双字节长度的缓存区,同时记录已读取位数
(每读取一个字节自增 8),当已读取字节超过一个「固定数值 」A(初始为 9)后,
从缓存区读取出 A 位数据,当作双字节数据返回。
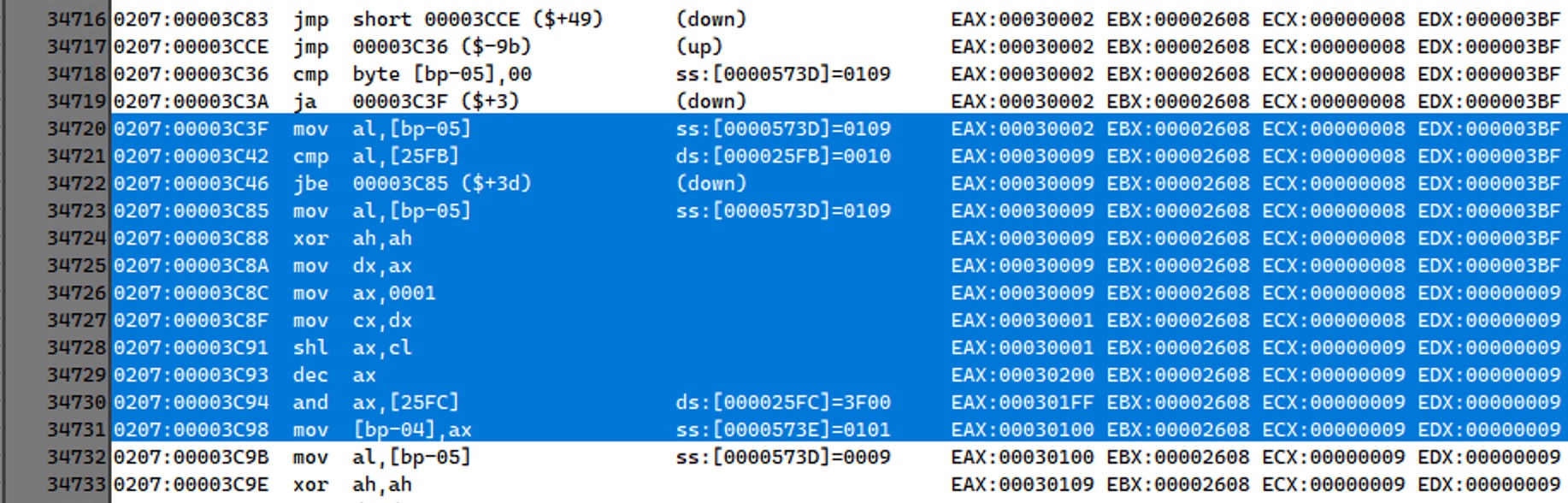
上面就是我们读取到的第一个索引 100h,首先我们读了两个字节,保存了 16 位数据,
然后从 16 位数据中取出 9 位,作为我们的第一个结果,那么接下来我们应该就会有以下疑问。
为什么每次 9 位数据?
对于 256 色来说,一个字节正好可以保存一个像素,9 位数据反而拉长了存储量, 回答这个问题,需要了解图像保存的机制,首先是即时字典。
什么是即时字典
程序在不断读取文档的同时,会自行创建一份字典,对于小于 256(0100h)的数据,
直接当作是像素输出,对于大于 257(0101h)的数据,则会通过查阅字典,
来输出最终的像素。很显然我漏了 256 和 257,这两个是控制字符,不会输出实际像素,
我最早推测 256 为开始,257 为结束。
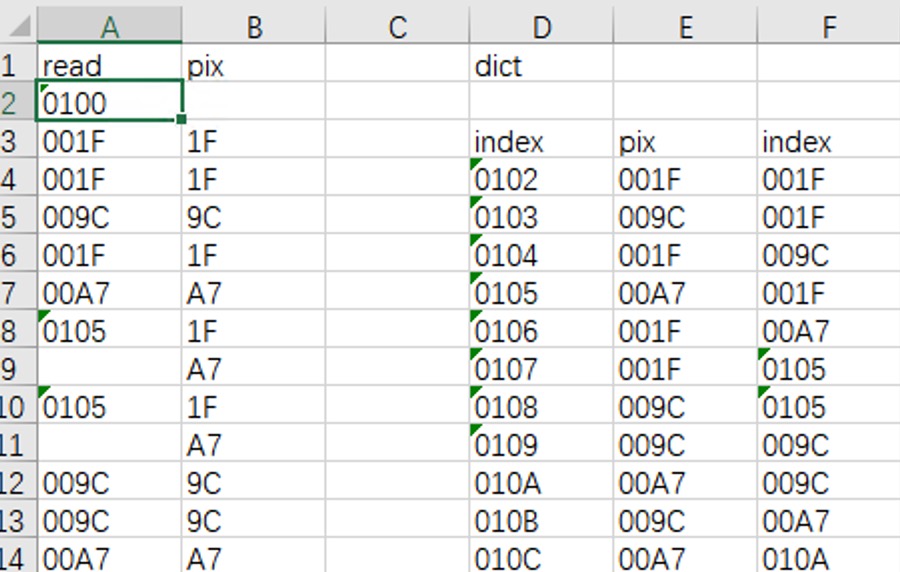
上图分别列出了第一幅图的三组数据,第一列是程序从文件中读取的索引值, 第二列是程序输出的像素点,剩下三列就是在读取过程中,程序自行建立的字典。
字典内容如何编制
字典是根据已写入的内容编制的,比如,写入两个像素 1f、1f 后,
程序检测到前两次写入的数据还没有写入字典,就会创建一个条目 258(0102h),
这样后续读到 258 后,程序就会直接写入 1f、1f 两个像素,
从而达到了压缩数据的效果。
思路很简单对不对,但是实践时这里面会有很多坑:
字典条目可嵌套
为了方便理解字典我描述的是最简单的情况,但实际上字典远不止这样简单,
字典条目是一个双字节索引,保存的内容是三个字节,一个字节是最后写入的像素,
另外两个字节是上次写入的索引,这样一来,后续一个索引可以输出更多个像素。
比如,我们接着上面的例子,如果再写入一个 1f 后,程序会创建条目 259,
值为(1f,258),这样后续读到 259,程序会连续输出 1f、1f、1f 三个像素。
读取到未录入字典的索引
这是一个非常坑人的地方,我们居然会读到未录入字典的索引!不过所幸还有规律可循, 我们知道字典的索引是自增的,当我们正好读到下一个待录入的索引号 (如果接续上面的例子,会是 260)时,我们需要自行创建这个索引, 其值为(最后写入的像素,最后写入的索引)
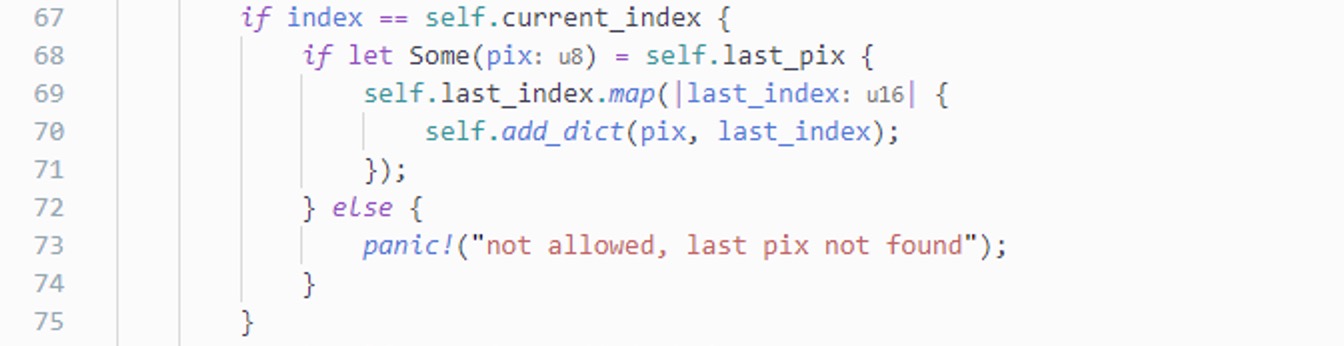
什么是最后写入的像素
「最后写入的像素」是我的解释,这个解释虽然便于理解,但最终对我造成了误导,
一方面也说明了读取过程没有那么直白,所以我也把它拎了出来。
如果每次只写入一个像素,这个定义也毫无问题,但是如果读取一个索引后,
我们依次写入了像素 a1、a2、a3,根据字面意思,最后写入的像素应该是 a3,
但实际上程序记录的像素是 a1,这一点很关键,既影响嵌套索引,也影响未录入索引。

从上图可以看出来,最后写入的像素是我们 push 进去的第一个像素。
字典索引的上限
先给一个噱头,索引的上限介于有跟没有之间。
如果还记得读取的时候我们讲到了一个固定数值 9,相信大家都会和字典索引联系起来:
字典索引的上限是 511(01FFh),超过这个数值,我们就读不出来了。
是的,但是索引的上限并不是 511,只是当索引超过 511 之后,
我们每次从缓冲区读取的位数就不是 9 位了,而是 10 位,同理,
当索引上限超过 03FFh 后,读取位数还会增加。当然这个增加也不会是无节制的,
我们的缓存区一共也只有两个字节,所以索引值不会超过 65535,但实际上,
索引值大于 11 位以后,读取位就强制不增长了:

所以最大索引应该是 07FFh,也就是 8k 个。而程序中还有一个机制来控制索引数量,
那就是控制字符 0100h
控制字符
通过 DOSBox 的 CPU log,我们可以提取出完整的文件读取结果,由于这个过程很长,
人工核对比较困难,我上下扫了一眼,发现第一个是 0100h,最后一个是 0101h,
就简单的推断,0100h 是开始标记,0101h 是结束标记,但在实际读取中会发现,
读取过程中也会读到 0100h,那么很显然 0100h 就不能当作文件的开始标记了,
不过也很好推测,0100h 是重设标记,读取到 0100h 后,
程序会清除先前保存的字典和索引,重新从 0102h 开始建立字典,
相应的读取位数也会回归到 9。
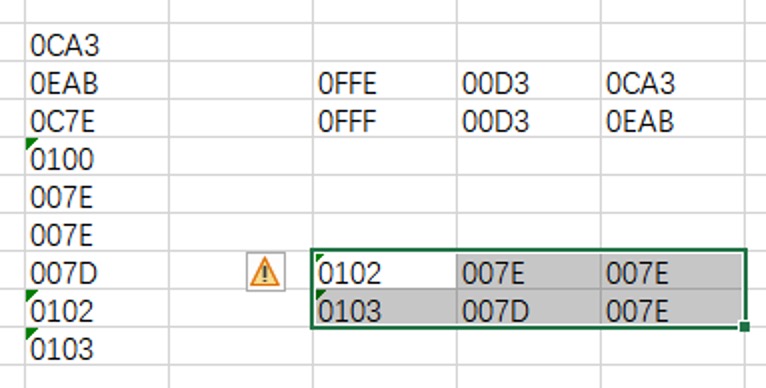
控制字符的存在,让字典索引的上限变得没那么重要,如果觉得索引太多了,
编码时加入一个 0100h,一切就会从头开始,当然代价就是索引需要重新建立,
这就是为什么说索引的上限介于有跟没有之间,机制和程序都明确给出了索引的上限,
但控制字符又让这个上限不太有意义,理论上,有了控制字符应该就不需要强制上限了,
不过程序确实存在了这两种机制。
shld / shrd
是我最初也是我最后踩到的坑,这是两个汇编指令,类似于位移,与位移的区别在于,
普通的左移右移直接用 0 补位,而 shld / shrd 会依据另一个参数的值补位:
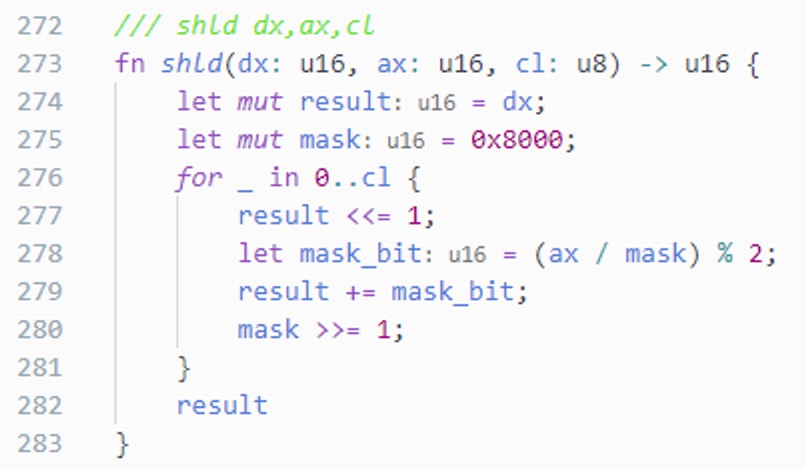
一开始理解这两个指令花了不少时间,理解完了发现多数传入的另一个参数都是 0, 就把它简化成普通位移,但是后面发现,补位还是用到了, 所以我们还要记录补位数的结果。
最后
上面的坑都踩一遍后,我们终于可以解析出全部的像素了,读取长度 111426, 像素长度 222593,压缩率 50%,感觉还可以,顺带一提,根据像素长度,我们可以推出, 图像的分辨率是 640 x 359。

接下来我们就要确定调色板,给灰姑娘上色了,调色板应该很简单对不对,不好意思, 虽然跟本篇比算不上什么,但也不能一蹴而就,这期内容已经太多了,我们下期再见吧。