夜行侦探 EVE burst error 游戏文件分析(八)
基本上我们的思路已经出来了,那么接下来我们要来证明我们的思路是可行还是不可行,不可行的话,是为什么不可行
目录
本系列基本完结,以下是目录供快速翻阅:
- 启动、GDT 文件分析一:19 个函数
- GDT 文件分析二:ghidra 偏移量、读取、初次绘画
- GDT 文件分析三:多次读取、偏移量、调色板
- GDT 文件分析四:完整解开及遗留问题
- 游戏文本解码
- 汉化方案制定
- 游戏文本编码
- 汉字日文编码、字库、以及第一个汉化文件
- 配置一个汉化 demo
- 手机游玩、程序文字汉化
GB2312 vs Shift-JIS
EVE 的编码没有疑问是 Shift-JIS,这个编码是通过日文的「区位码」算出来的, 对应的公式可以查阅维基百科:

顺带一提,中文的维基百科过于简单了,建议看日文或英文的版本做进一步了解。 在公式中 j1j2 是「区位码」,s1s2 为 Shift-JIS 编码。为什么「区位码」加引号, 因为可能正确的叫法是区点码,但是 GB2312 中的原始编码叫区位码, 我们接下来要用到这个,就是把日文的区位码,换成国标的区位码。
为什么要这么做,因为 dosbox-x 的 FREECG98.BMP 的字库,基本就是按日文「区位码」来排列的:
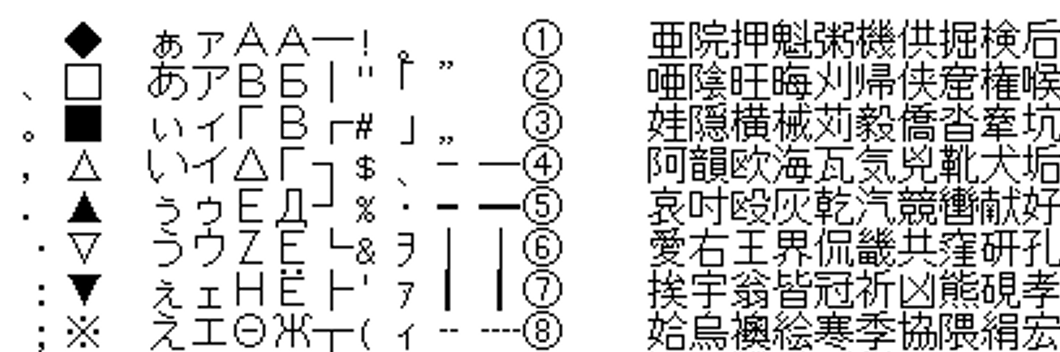
每列一区,共 94 区,每区 94 个字。神奇的是,GB2312 也是 94 区 94 字, 当然其实这应该不是巧合,JIS 的制定早于 GB2312,所以 GB2312 应该参考了 JIS 的指定方法, 或是两者都参考了相同的制定标准,这个不是我们研究的目标,就此打住。
从 JIS 的转换公式,我们很难看出如何从 Shift-JIS 编码推断日文「区位码」, 但是显然 dosbox-x 内置了这个转换方法,所以才可以从 Shift-JIS 编码的文字内容找到正确的文字图像。
所以我们的思路是,把 GB2312 的编码文字,换到 FREECG98.BMP 中, 然后把翻译文本先从 GB2312 编码解释为汉字区位码,然后把汉字区位码当成日文「区位码」, 计算出对应的 Shift-JIS 编码,替换掉原来的日文文本,重新生成 cc 文件, 对于游戏的第一个 cc 文件,是 A01.CC。
那么我们的第一步是,制作国标版 FREECG98.BMP:

同样是每列一区的做法,换上去以后,FREECG98.BMP 的初版就制作完成了。
重新检查 FREECG98.BMP
有这个标题,你就一定会猜到,事情没那么简单,因为我在游戏中遇到了这个:
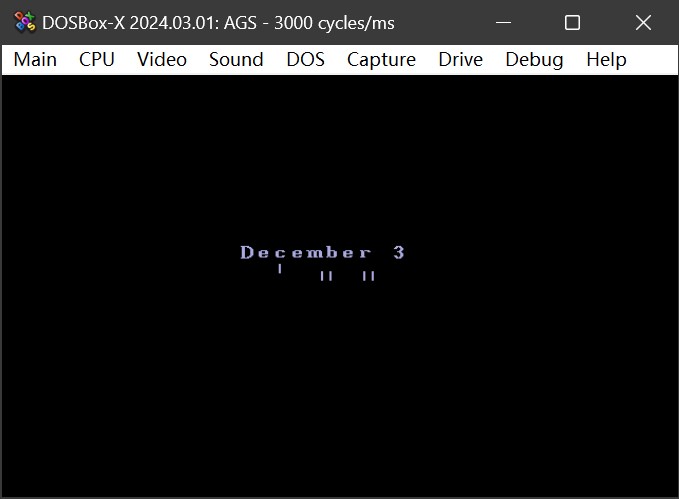
下面一排是一串日期,全是半角字符,但是现在变成了乱码。与此同时,上面的全角字符都是正常的, 为此我还专门试验了一下 0-9 的数字:
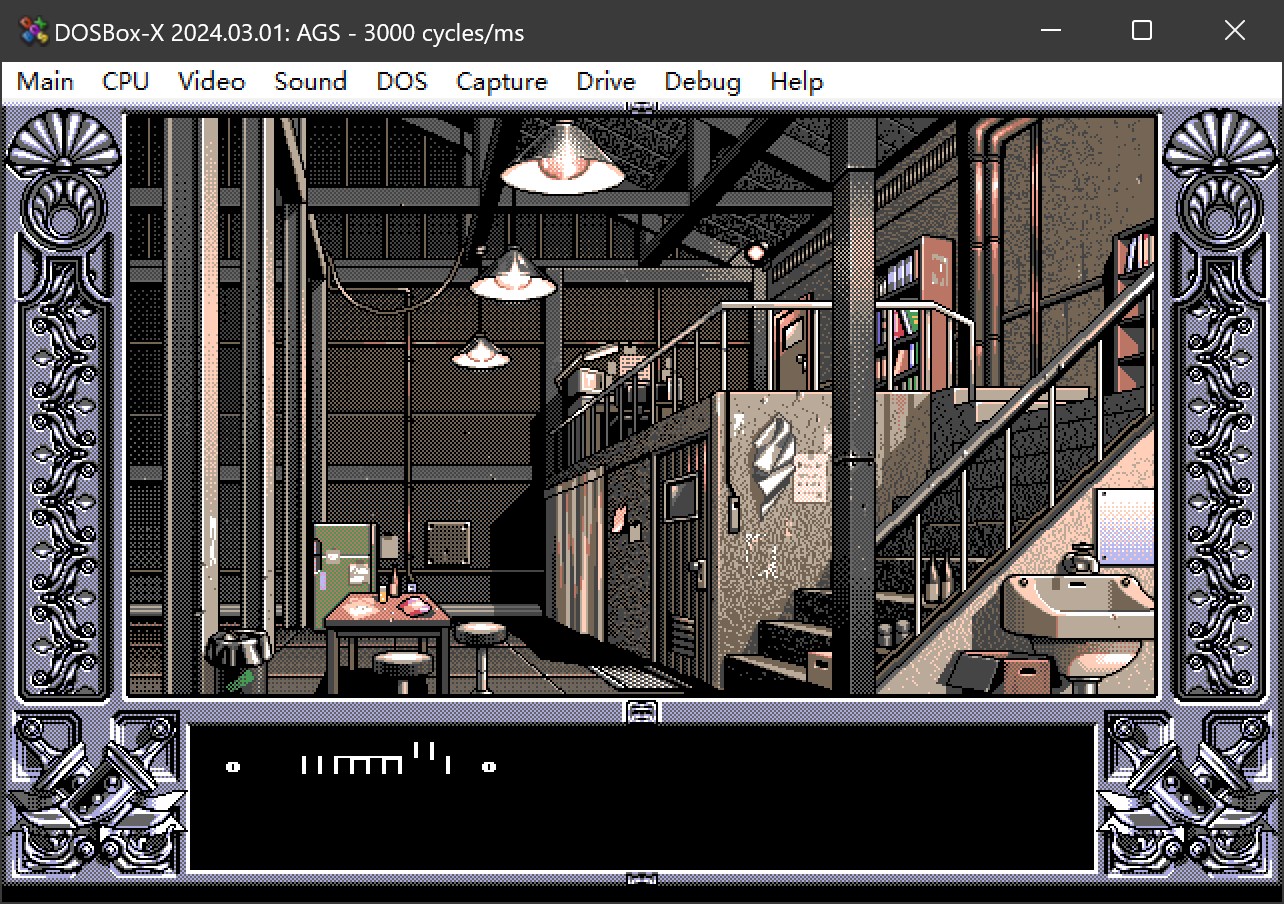
两个句号间是 0-9 的数字,全是小蝌蚪了。
这个问题很难想出是哪里出了问题,因为理论上,半角数字的英文、中文、日文的编码应该都是相同的, 而看 FREECG98.BMP 的实际图形,应该也是用第一排来显示半角符号,而这排我们完全没有修改过:
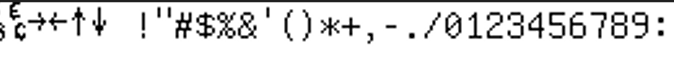
想了两天,终于想出了一个方法:回到日文版 FREECG98.BMP,然后把数字都做上标记, 然后看日文版的 0-9 是如何显示的,结果发现,其实 FREECG98.BMP 并没有用第一行图像去画数字, 而是隐藏在「区位码」第九区中:
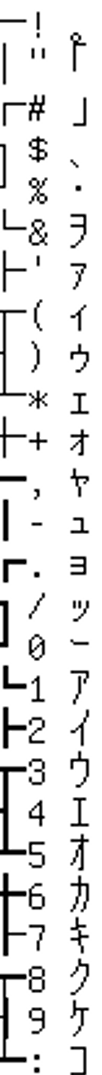
虽然格子大小还是 16x16,但是很显然只用了一半,而 GB2312 的第九区,是制表符:
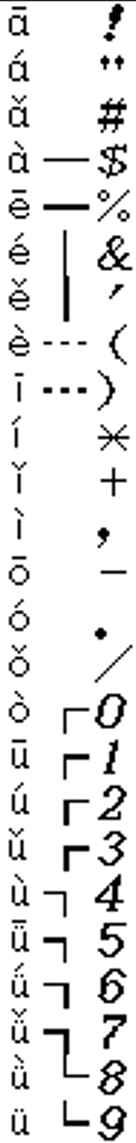
因为只显示了一半,所以我们看到了很多蝌蚪文,那制表符我们应该是用不到的, 直接换成日文的半角字符就好,然后我这个中文字库很奇怪地有两排全角数字,我就做了个位移, 把制表符向后挪了一位,最后的国标版 FREECG98.BMP 长这个样子:

这样显示半角字符的问题也解决了,至于为什么 FREECG98.BMP 要整这么一出,不在我们的研究范围,解决就好。
A01.CC 文本翻译
文本翻译的做法我们提过,解码 A01.CC 得到原始数据,
然后找出全部符合 FD [长度] [数据] 的内容作为文本,翻译后,
替换掉原始数据中的文本,重新压缩得到 A01.CC。实际我就是按这个做法操作的,
不过细节上,翻译后我保存的格式为 GB2312,然后使用程序进行一次转换(GB2312 → 区位码 → Shift-JIS),
然后再替换原始数据的文本。GB 转区位刚才没有提到,很简单,原始编码减去 0x80 即可,
细节可以自行查询 GB2312 的编码方式。
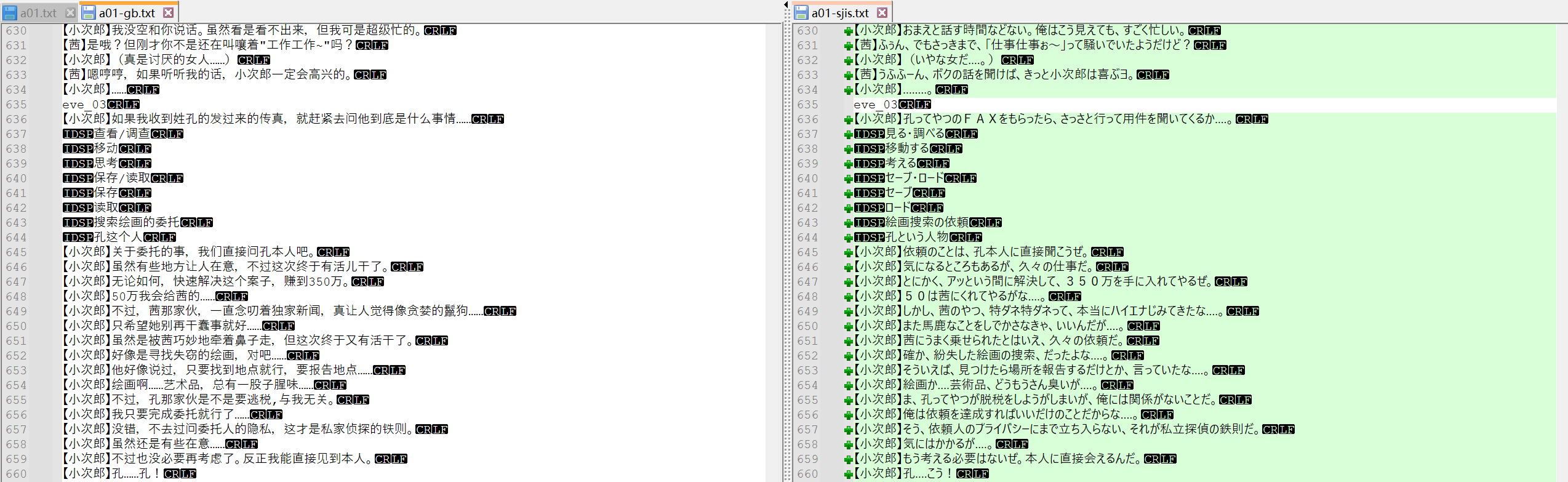
基本上我是这样做翻译的:把日文大段丢给 AI,然后一句一句贴回 gb 文件。听上去很容易, 实际操作很繁琐,而且因为文字太多,容易出错,总结一下容易出错的点:
1. 换行符
这个 txt 文件的格式是我定的,以 \r\n 为换行,因为我发现游戏中有时候会用 \r 来换行,
但此时字符串并没有结束,而我需要一个分隔符来分割文本,游戏中正好没有用到 \r\n,所以就以 \r\n 为换行。
于是引发了另一个问题,VSCode 会自作聪明地把所有 \r 转为 \r\n,
这样字符串个数和内容就都对不上了,所以眼尖的朋友应该发现我启用了 Notepad++,
我只知道这个编辑器是可以显式标记所有不可打印字符的,而且它完全不会去自己转换换行符,
我甚至都不知道如何在 Notepad++ 中修改换行符,我都是找到以后再切到 ImHex 去做修改。
重申翻译文本中的换行,以及文本分隔符,一定要与日文原稿中完全一致,如果不一致, 进游戏会错得很离谱,因为字符串乱了。当然这个确实还是很容易错,我错了好多回,都是这个原因。
2. 不可打印字符
不可打印字符要找合适的位置原样抄回去,不然一样会影响游戏流程:

这是使用 Notepad++ 的另一个原因,便于观察不可打印字符,上面这段译文就引发过游戏后面选项完全错乱的问题。
3. 特殊字符不可有
之前在译文中敲了个 &,结果错得莫名其妙,编程中有特殊含义的字符避免使用。 然后就是日文的标点比如省略号和中文是不同的,建议手工敲……
总结
话不多说上视频(youtube,谢绝转载):
基本上 A01.CC 的内容已经全部中文化了,中间有一些乱码,推测是程序里的文字, 不影响功能的话就后续再说了,如果后面一直都很顺利的话,估计这个系列就会完结了, 接下来我可能就是写一篇如何还原这个演示的功能,给感兴趣的朋友试试, 话说 CC 文件有 94 个,翻译一个需要两天的话……我们半年后再见吧。
有了 AI 的帮助,现在一个人可以做更多事了,这在以前是想也不敢想的, 不过 AI 的质量还不是很高就是了,各位翻译朋友还不需要太担心,很多翻译内容我自己都觉得差点意思。