使用字典压缩大模型的提示词
今天我们要为一个大模型的信众朋友解决一个问题,如何把大表格塞入大模型的上下文中。
背景
现在这个时代,很多人开始追逐大模型的风口浪尖,大模型的技术又比较复杂,对于很多人 来说就像是一个黑箱。在见识了大模型的一些能力之后,开始有人产生了类似图腾膜拜的感 觉,认为大模型可以做任何事情。于是呢,我就收到了这么一个需求,把表格喂给大模型, 然后让大模型分析数据。
分析
我个人主观上不是很推荐用大模型分析表格,这不是它擅长的事情,以我的观察,它理解不 了数字的变化和之间的关系,多数情况下我觉得它是预设了一个立场,然后阐述这个立场。 不过我们这次的目的就是要把表格喂给模型,所以需要跳过我的主观判断直接下一步, 但是我觉得应该把丑话说在前头,起码表达下我的预设立场。
如何把大表格塞进上下文,我觉得可以从这几个方面下手:
1. 尽量大的上下文
模型一般都有一个以 token 数量计数的上下文,如果是对大模型比较陌生的朋友, 可以简单理解一个 token 就是一个字。为了塞大表,肯定是要上下文足够大, 这是个基础条件,表格数据起码和上下文的数据要在一个数量级上, 这样我们才能继续考虑压缩表格的事情。一般个人用户常用的本地大模型工具是 ollama 或 各种 llama.cpp 的套壳,每种调整上下文大小的方法不尽相同,但是方法是差不多的, 我使用 LM Studio 举例:
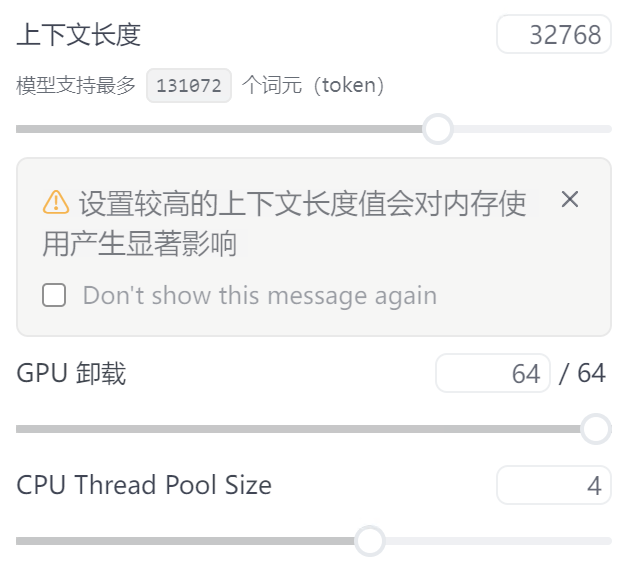
我这台机器,32768 上下文模型开得起来,但是 65536 就不行,我们可以通过二分法逐步 去找这个边界,最后大概停在 53248 附近。这个上下文大小,基本上我们放一个 53k 的表 格 csv 是没问题的。
为什么说 53k 上下文装 53k csv,细心的朋友可能会发现这里的不严谨,是的, 第一个 53k 是 token,而 csv 这个 53k 是字节大小,两者其实没什么可比性,这两个概 念都被我强行简化了,一般说来,一个中文 token 大概是 3 到 4 个字节,而 utf8 一般 是三字节一个字,所以两者大致是这样一个关系,这样看来,csv 转换成 token 的数量大 概是一两万左右,剩余的上下文可以作为给其他提示词或是大模型回答我们问题所需要的空 间。当然我的水平有限,这个说法是有问题的,只能解释大致的情况,如果读者朋友对这个 非常感兴趣,可以去看看分词器(tokenizer)的相关文章,我不了解这些内容,就不再献 丑了。
这里再顺带提一提如何让大模型认得表格,因为目前我们常用的大模型还是文生文为主,也 就是说它只认得字,也只能输出字,那么我们丢给大模型一个原始的电子表格文件,它是不 认得的,我们要把表格转成 csv 或者 markdown 格式的纯文本形式,才能输入模型,如果 有些工具允许我们输入一些其他非文本格式的电子表格,那么多半是这些工具对表格文件做 了预处理,而不是模型本身有这个能力。有些工具甚至允许我们输入超过上下文的表格,那 么这个表格一定是经过类似 RAG 的处理,实际输入模型的只是几个表格内容的片段或是摘 要总结,也不是模型本身的能力。
2. 删除不相干的栏位
可能很多年长的朋友听过这个电脑笑话:删除是压缩文件的最有效的方法,这是个笑话,但 是不代表完全没有道理,如果文件内容没有什么价值,那么我们确实可以删掉它,来省下全 部的空间。那么为了把表格数据放入上下文,我们也可以利用这种方法,把与我们的分析目 标不相干的栏位去掉,来大幅降低表格的长度,移除不相干的栏位也可以避免模型在错误的 维度来分析表格。
3. 引入字典
字典是压缩文件算法中常用的做法,找出文件中重复的片段,给出一个编号,然后用这个编 号取代所有文件中的这个重复片段,这样就降低了文件的空间占用。同样如果我们的表格中 也有较长的重复出现的文字,我们也可以给它一个编号,来把它们全替换掉。比如我们有这 样一个表格:
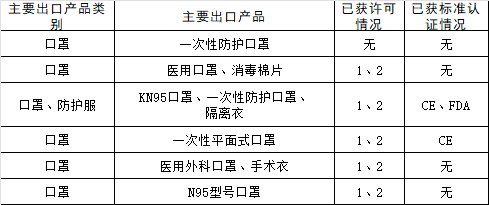
出口产品和类别很多都是重复文本,这个时候,引入字典就是一个不错的办法了,比如我们 把「一次性防护口罩」编号为 A,那么表格中的所有相同的文本都可以替换为 A。当然我们 在提示词中要告诉模型,ABCD 分别是什么意思。
模型对这种程度的转义理解还是没有问题的,不过在回答问题时,模型比较喜欢用「一次性 防护口罩(A)」这种形式来标记一下对应文字。刚开始我还挺不习惯的,甚至想提示它去 掉这部分内容,不过后来想想这似乎也没什么不好,我们还可以检查一下它有没有犯转义替 换的错误。
对于我个人的用例,原本只使用(一)和(二),我只能把某一个小区域的某种类型的数据 塞进去,现在三管齐下,我塞进去了另一个较大区域的全部数据,听着是不是还挺管用的? 不过两个区域虽然数据量差别很大,不过还是在几百的数量级内。
总结
这个做法虽说是本文的标题,不过我觉得是三种做法中最次要的做法,也是同样的原因, 我把它放在最后介绍,引入字典只是一种软实力,上下文长度和删除栏位我认为是硬实力的 做法,如果这两个做法我们已经用过,但是表格大小还是差那么一点点才能塞进上下文,那 么这时候我们才需要考虑字典,根据以往分析 LZW 压缩资源的情况,这种做法充其量也就 是做到 50% 左右的压缩率,基本上就是相同数量级再小一点,如果表格大小与上下文长度 相差太大,那就不要对字典报太大希望。