从 llm.c 到 llm.rs(二)
所有的程序都应该从 main 开始,那么我们也从 main 看起
GPT2 模型
main 函数首先做了这么一个事情
// build the GPT-2 model from a checkpoint
GPT2 model;
gpt2_build_from_checkpoint(&model, "gpt2_124M.bin");
根据注释,首先声明一个模型,然后把模型从 checkpoint 构建出来, 那么我们先看 GPT2 这个结构
typedef struct {
GPT2Config config;
// the weights of the model, and their sizes
ParameterTensors params;
size_t param_sizes[NUM_PARAMETER_TENSORS];
float* params_memory;
int num_parameters;
// gradients of the weights
ParameterTensors grads;
float* grads_memory;
// buffers for the AdamW optimizer
float* m_memory;
float* v_memory;
// the activations of the model, and their sizes
ActivationTensors acts;
size_t act_sizes[NUM_ACTIVATION_TENSORS];
float* acts_memory;
int num_activations;
// gradients of the activations
ActivationTensors grads_acts;
float* grads_acts_memory;
// other run state configuration
int batch_size; // the batch size (B) of current forward pass
int seq_len; // the sequence length (T) of current forward pass
int* inputs; // the input tokens for the current forward pass
int* targets; // the target tokens for the current forward pass
float mean_loss; // after a forward pass with targets, will be populated with the mean loss
} GPT2;
除了基本类型,还涉及到以下这么几个结构:
GPT2Config
typedef struct {
int max_seq_len; // max sequence length, e.g. 1024
int vocab_size; // vocab size, e.g. 50257
int num_layers; // number of layers, e.g. 12
int num_heads; // number of heads in attention, e.g. 12
int channels; // number of channels, e.g. 768
} GPT2Config;
这个很简单。
ParameterTensors
// the parameters of the model
#define NUM_PARAMETER_TENSORS 16
typedef struct {
float* wte; // (V, C)
float* wpe; // (maxT, C)
float* ln1w; // (L, C)
float* ln1b; // (L, C)
float* qkvw; // (L, 3*C, C)
float* qkvb; // (L, 3*C)
float* attprojw; // (L, C, C)
float* attprojb; // (L, C)
float* ln2w; // (L, C)
float* ln2b; // (L, C)
float* fcw; // (L, 4*C, C)
float* fcb; // (L, 4*C)
float* fcprojw; // (L, C, 4*C)
float* fcprojb; // (L, C)
float* lnfw; // (C)
float* lnfb; // (C)
} ParameterTensors;
参数张量这个东西就不太好理解了,看注释应该是矩阵或是一些概念类的定义, 而且我没办法用简单的 rust 结构去重建,我们现在知道它包含了一系列浮点指针, 后续要怎么写我们再看看如何初始化
ActivationTensors
#define NUM_ACTIVATION_TENSORS 23
typedef struct {
float* encoded; // (B, T, C)
float* ln1; // (L, B, T, C)
float* ln1_mean; // (L, B, T)
float* ln1_rstd; // (L, B, T)
float* qkv; // (L, B, T, 3*C)
float* atty; // (L, B, T, C)
float* preatt; // (L, B, NH, T, T)
float* att; // (L, B, NH, T, T)
float* attproj; // (L, B, T, C)
float* residual2; // (L, B, T, C)
float* ln2; // (L, B, T, C)
float* ln2_mean; // (L, B, T)
float* ln2_rstd; // (L, B, T)
float* fch; // (L, B, T, 4*C)
float* fch_gelu; // (L, B, T, 4*C)
float* fcproj; // (L, B, T, C)
float* residual3; // (L, B, T, C)
float* lnf; // (B, T, C)
float* lnf_mean; // (B, T)
float* lnf_rstd; // (B, T)
float* logits; // (B, T, V)
float* probs; // (B, T, V)
float* losses; // (B, T)
} ActivationTensors;
激活张量也是一样的情况。
读完这些代码,我有一个疑问,int 和 float 是多少位的?
推测是 4 字节 32 位,这一点很好验证,印出来就好
printf("[GPT-2]\n");
printf("max_seq_len: %d\n", maxT);
printf("vocab_size: %d\n", V);
printf("num_layers: %d\n", L);
printf("num_heads: %d\n", NH);
printf("channels: %d\n", C);
printf("int size: %lu, float size: %lu\n", sizeof(int), sizeof(float));
事实证明是 32 位。也就是我们会用到 i32 和 f32
gpt2_build_from_checkpoint
这个函数很长,我们简单摘要一下:
void gpt2_build_from_checkpoint(GPT2 *model, char *checkpoint_path)
{
// read in model from a checkpoint file
FILE *model_file = fopen(checkpoint_path, "rb");
...
// read header
int model_header[256];
fread(model_header, sizeof(int), 256, model_file);
// read in hyperparameters
int maxT, V, L, NH, C;
model->config.max_seq_len = maxT = model_header[2];
...
model->config.channels = C = model_header[6];
// allocate space for all the parameters and read them in
model->param_sizes[0] = V * C;
...
model->param_sizes[15] = C;
// count the number of paramaters
size_t num_parameters = 0;
for (size_t i = 0; i < NUM_PARAMETER_TENSORS; i++)
{
num_parameters += model->param_sizes[i];
}
model->num_parameters = num_parameters;
// read in all the parameters from file
model->params_memory = malloc_and_point_parameters(&model->params, model->param_sizes);
fread(model->params_memory, sizeof(float), num_parameters, model_file);
// other inits
model->acts_memory = NULL;
...
model->mean_loss = -1.0f; // -1.0f will designate no loss
}
看上去就是读取文件头,然后根据文件头内容申请参数内存,然后再读出参数,
那么有一些确定的东西以后,我们就可以开始写一点代码了。不过看到这里,
我觉得像我一样对大模型零基础的朋友们会问:maxT, V, L, NH, C 这几个东西是什么,
如果你仔细读代码,这几个值会对应到 GPT2Config 的几个成员,
不过大模型的事情,我还是问了一下大模型:
以下来自 claude:
maxT- 输入序列的最大长度(Maximum Token Length)。这限制了模型可以处理的最长输入序列。
V- 词汇表大小(Vocabulary Size)。这指的是模型词汇中唯一词元(token)的数量。
L- 层数(Number of Layers)。这指的是Transformer模型中的编码器/解码器层数。
NH- 每层注意力头数(Number of Attention Heads per Layer)。注意力头允许模型同时关注输入的不同部分。
C- 每个注意力头的维度或通道数(Number of Channels/Dimensions per Attention Head)。这决定了每个注意力头分配多少参数。
感觉信息是不是比变量名更丰富一点。不过这些没有相关知识,我想是读不懂的, 我们先放一放,首先我们先还原读取的过程。
读取过程
我们步子不要太大,整个文件头的大小是 1024 个字节,我们先把第一个魔法数读出来,
这是一个 int 表示的日期,占 4 个 byte,啰嗦一个细节原文没有提,
这个是 little endian 的。
let file_content = fs::read(path)?;
if file_content.len() < 1024 {
return Err("File is too small".into());
}
let header = &file_content[0..1024];
let magic_header = u32::from_le_bytes(header[0..4].try_into()?);
if magic_header != 20240326 {
return Err("Invalid magic header".into());
}
简单起见,我这里是把文件全读出来了。 魔法数没有问题,那我们就可以还原出配置的读取了。
fn from_header(header: &Vec<u8>) -> Self {
let max_seq_len = u32::from_le_bytes(header[8..12].try_into().unwrap()) as usize;
let vocab_size = u32::from_le_bytes(header[12..16].try_into().unwrap()) as usize;
let num_layers = u32::from_le_bytes(header[16..20].try_into().unwrap()) as usize;
let num_heads = u32::from_le_bytes(header[20..24].try_into().unwrap()) as usize;
let channels = u32::from_le_bytes(header[24..28].try_into().unwrap()) as usize;
GPTConfig {
max_seq_len,
vocab_size,
num_layers,
num_heads,
channels,
}
}
一共 5 个参数,接下来根据这些参数计算出 16 个参数张量的大小。
let param_sizes = [
config.vocab_size * config.channels,
config.max_seq_len * config.channels,
...
config.channels,
];
然后把全部的参数张量读出来,顺带一提,参数总量是 124439808, 这应该就是 gpt2_124m.bin 中 124m 的由来。
let wte_start = start;
let wpe_start = wte_start + param_sizes[0] * 4;
...
let lnfb_start = lnfw_start + param_sizes[14] * 4;
ParameterTensors {
wte: Self::get_param_vec(content, wte_start, param_sizes[0]),
wpe: Self::get_param_vec(content, wpe_start, param_sizes[1]),
...
lnfb: Self::get_param_vec(content, lnfb_start, param_sizes[15]),
}
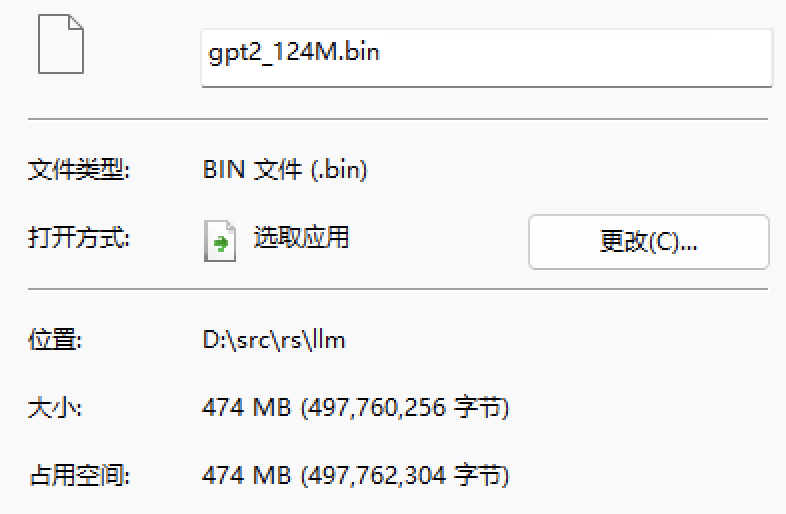
注意参数张量在文件中的起始位置是 1024,参数张量总计 124439808 个,
每个都是 f32,那么总计需要读取 497759232 字节,加文件头 1024 为 497760256,
正好是整个文件的大小:
总结
我们读完了整个 gpt2_124m.bin 文件,休息一下吧。这个文件包含了一个文件头, 保存了 gpt2 模型的基本配置,其他部分则是保存了完整的参数张量。