夜行侦探 EVE burst error 游戏文件分析(六)
这篇虽是因 eve 而起,但是其实和 eve 没有直接的关系,但是感觉也不想它作为孤立的一环, 所以想来想去,还是当作是 eve 的第六篇。
目录
本系列基本完结,以下是目录供快速翻阅:
- 启动、GDT 文件分析一:19 个函数
- GDT 文件分析二:ghidra 偏移量、读取、初次绘画
- GDT 文件分析三:多次读取、偏移量、调色板
- GDT 文件分析四:完整解开及遗留问题
- 游戏文本解码
- 汉化方案制定
- 游戏文本编码
- 汉字日文编码、字库、以及第一个汉化文件
- 配置一个汉化 demo
- 手机游玩、程序文字汉化
棘手的问题
上一期我们找到了游戏中的文本,那么接下来我们可以考虑如何中文化的问题了。
最初我的想法很简单,那么多日文汉字,直接引用不就够了,后来发现这个想法太天真,比如「你好」
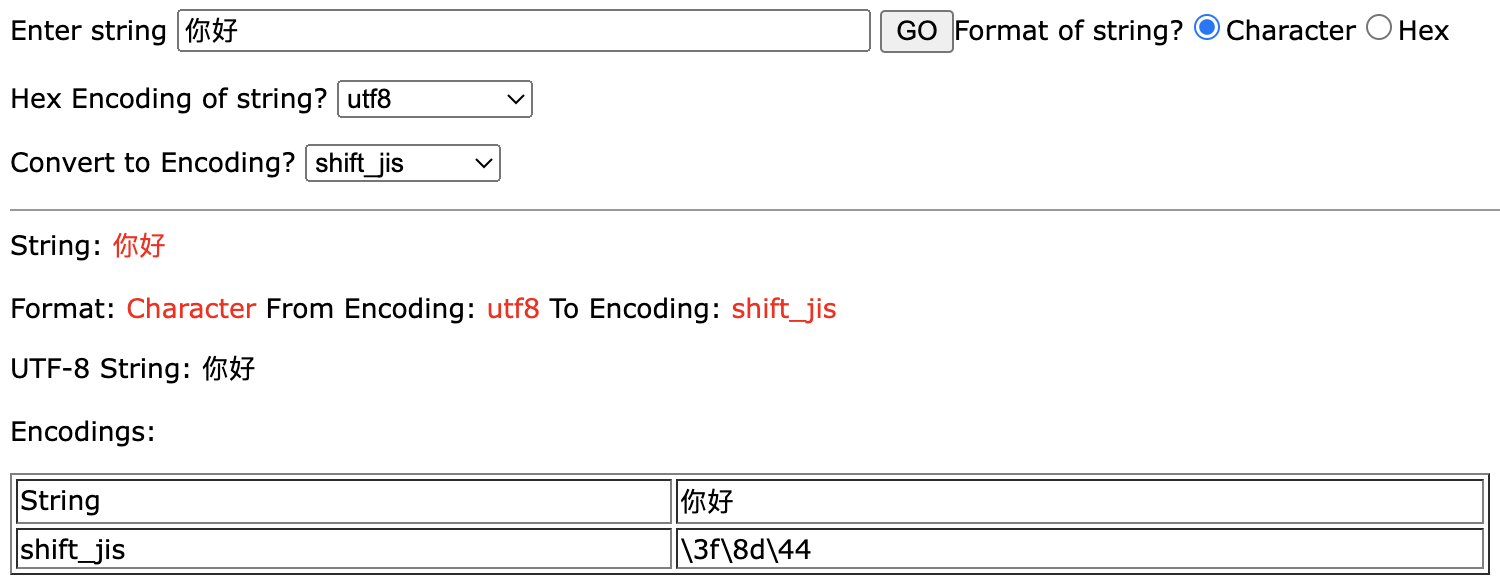
3f 在 ascii 中是「?」,也就是说,shift-jis 没有「你」这个字,那我总不能写「君好」吧。 日文的常用汉字和中文的常用汉字不匹配,那我们的难度就又提升了,我们需要挂一个字库, 或者找出现有字库替换掉。
第一个方案我就不考虑了,水平有限,因为外挂字库我估计是要修改代码,看代码我就很费劲了, 改代码估计还会引入新的问题,可能提取出所有资源自己做一个,可能也比挂个字库要好办。
第二个方案,经过我的一番了解后,感觉也很困难,因为 pc98 是硬件包含日文字库的, 换句话说,游戏中可能本身就没有字库,能显示文字是使用了硬件字库。
有没有感觉到问题的棘手和我的沮丧,看上去两条路似乎都行不通,感觉我的小目标要远离我了, 不过虽然我的字典里有放弃两个字,但是也没有很容易就找到,我又去研究了一下 dosbox-x 的 pc98 机制。
PC-98 font and accessory files
You can start DOSBox-X in PC-98 mode without any additional files apart from the DOSBox-X executable itself. Note, however, that in order for DOSBox-X to display Japanese characters (Kana, Kanji, etc.) correctly you may need to supply a font file. While optional (the internal Japanese DOS/V font will be used if no other font found, unless the TrueType font output is used, see below), it is still recommended using a font file specifically designed for PC-98. You can either use the original PC-98
FONT.ROMROM file, or use the free alternativeFREECG98.BMPincluded with DOSBox-X. Put theFREECG98.BMPfile or the original PC-98FONT.ROMfile in the DOSBox-X directory, then DOSBox-X will render Japanese texts in the PC-98 mode using this font (if bothFREECG98.BMPandFONT.ROMfiles are found in the directory then the latter will be used):
- FREECG98.BMP: Download here
{kind=link}
原来 dosbox-x 的 pc98 模式,也是挂一个字库 FREECG98.BMP,而且这个字库可以定制。 那么是不是我们可以利用这个机制,来挂上一个中文字库?为了利用这个机制, 首先我们得试验一下,EVE 是否使用了 dosbox-x 的字库,我们知道开头是这样的:
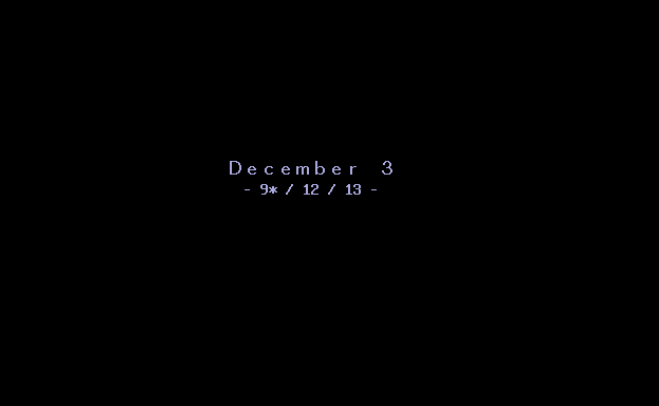
那么如果我们修改一下 FREECG98.BMP,这个结果如果体现到游戏中,那就说明程序用到了这个字库, 比如我们给「D」加个点,注意游戏中的「D」是全角的:

然后重启进游戏看看:
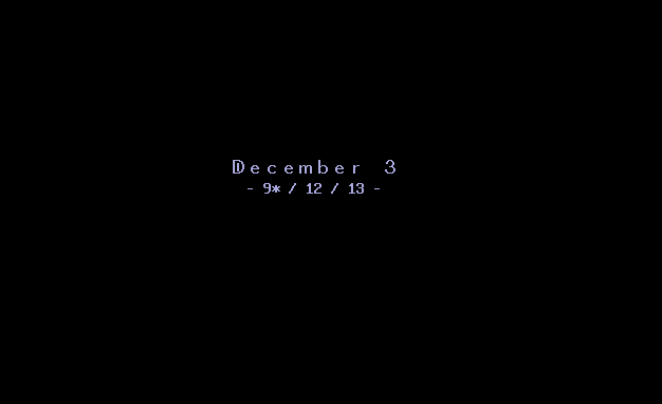
好的,那么看来我们有了一条新路可以走:
- 生成包含 GB 编码汉字的 FREECG98.BMP,替换原 BMP 文件
- 将游戏文本翻译为中文
- 生成 GB 编码的 A01.CC 文件
但是其实这里面还有一个问题,现行使用较多的 GB 编码,字节码是大于 0xA0 的。
因为这样很容易识别哪些是 ASCII,哪些是 GB2312,因为 ASCII 字符不会超过 0x7F,
但是 FREECG98.BMP 并没有这么大的空间,它只容纳了 0x7F 之内的双字节字符。
我们需要使用 ISO 2022-CN(国标) 的编码方式,把字符编码控制在 0x7F 以内。
生成 GB 版 FREECG98.BMP 的思路
生成 GB 版的 FREECG98.BMP 不难,但是因为我们需要验证的文本,所以我们可以放一放, 我这里简单总结下涉及的一些要点,以及思路:
- FREECG98.BMP 第一排记录了半角符号(8x16),对应 ASCII 的 0-255
- FREECG98.BMP 其余排为全角符号(16x16)
- FREECG98.BMP 的尺寸为 2048x2048,故只能覆盖
0x80,0x80以内的编码 - 由于原 FREECG98.BMP 记录的是 16x16 大小的文字,所以我们也需要 16x16 的中文字库,这个很容易找,一般文件名叫 HZK16
- HZK 分 94 区,每区 94 个汉字,每个字节代表八个点,只用了前 87 区
- HZK16 中,每个 bit 代表一个点,32 个字节代表一个字(
32x8 = 16x16),故 HZK16 的大小至少为:87x94x32 = 261696 - HZK16 汉字复制到 FREECG98.BMP,须按照 国标码 编码方式(拟)
- 常用 GB 编码双字节均大于
0xA0,须转换为 国标码
总结
总结下我中文化的方案:
- 生成国标版 FREECG98.BMP
- 生成国标版 A01.CC
这样,感觉就可以做到中文化了,不晓得各位是否觉得怪异,但是我觉得如果这篇看下来, 似乎是最为简易的方式,不过还需要我们后面的验证。